28. 그래프의 깊이 우선 탐색
28.1 도입
- 탐색(search) 알고리즘: 트리의 순회와 같이 그래프의 모든 정점들을 특정헌 순서에 따라 방문하는 알고리즘들
- 정점들을 정해진 순서대로 둘러보기 위한 알고리즘, 순회 알고리즘
- 탐색 과정에서 얻는 정보가 아주 중요
- 탐색 과정에서 어떤 간선이 사용되었는지, 또 어떤 순서로 정점들이 방문되었는지를 통해 그래프의 구조를 알 수 있다.
28.1.1 깊이 우선 탐색(depth-first search)
깊이 우선 탐색(depth-first search, DFS) 는 그래프의 모든 정점을 발견하는 가장 단순하고 고전적인 방법
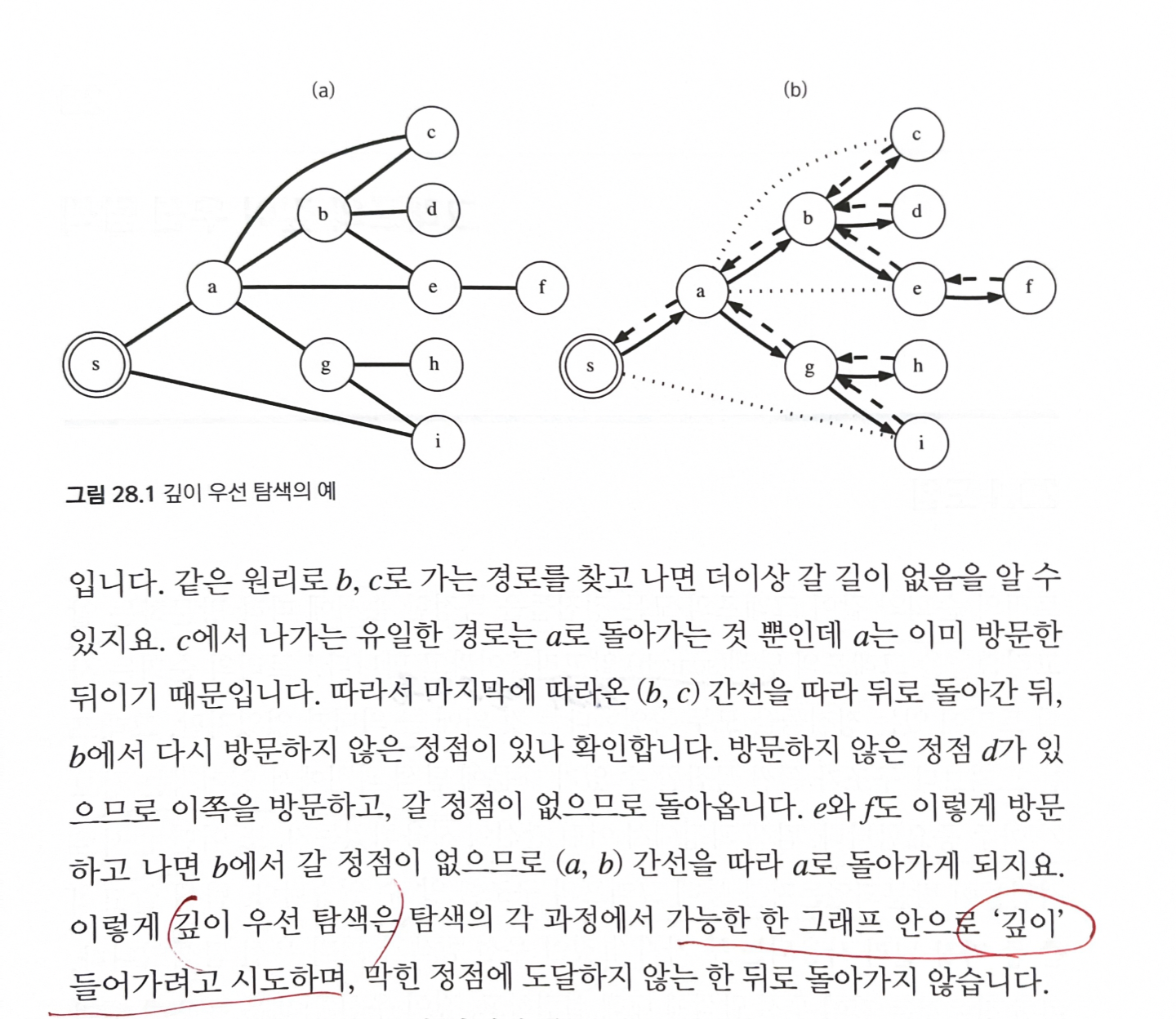
깊이 우선 탐색은 그래프의 시작 노드에서 출발하여 탐색할 한 쪽 분기를 정하여 최대 깊이까지 탐색을 마친 후, 다른 쪽 분기로 이동하여 다시 탐색을 수행하는 알고리즘.
현재 정점과 인접한 간선들을 하나씩 검사하다가, 아직 방문하지 않은 정점으로 향하는 간선이 있다면 그 간선을 무조건 따라간다.
이 과정에서 더이상 갈 곳이 없는 막힌 정점에 도달하면 포기하고, 마지막에 따라왔던 간선을 따라 뒤로 돌아간다.
탐색의 각 과정에서 가능한 한 그래프 안으로 ‘깊이’ 들어가려고 시도하며, 막힌 정점에 도달하지 않는 한 뒤로 돌아가지 않는다.
더 따라갈 간선이 없을 경우 이전으로 돌아간다.
지금까지 방문한 정점들을 모두 저장(기록) 해야 한다.
재귀 호출을 이용하면 이와 같은 일을 간단히 할 수 있게 된다.
‘기본’ 적인 재귀, dfs 코드
얼마든지 문제에 따라 변형 할 수 있어야 한다.
| |
- ‘기본’ 적인 반복문, dfs 코드
| |
그래프에서는 모든 정점들이 간선을 통해 연결되어 있다는 보장이 없기 때문에,
dfs()만으로는 모든 정점을 순서대로 발견한다는 목적에 부합하지 않는다.dfsAll()로 모든 그래프 조각을 발견(탐색)한다.
깊이 우선 탐색은 그래프 전체의 구조를 파악하기 위해 사용,
- 그래프의 구조상 한 번에 모든 정점을 다 볼 수 없는 경우에도 모든 정점을 다 방문할 필요가 있다. =>
dfsAll()
- 그래프의 구조상 한 번에 모든 정점을 다 볼 수 없는 경우에도 모든 정점을 다 방문할 필요가 있다. =>
28.1.2 깊이 우선 탐색의 시간 복잡도
인접 리스트의 경우
dfs()는 한 정점마다 수행되므로, 정확히 V번 호출모든 정점(V)에 대해
dfs()를 수행하고 나면 모든 간선(E)을 정확히 한 번(방향 그래프의 경우) 혹은 두 번(무향 그래프) 확인함따라서 깊이 우선 탐색의 시간 복잡도는 O(V+E)
인접 행렬을 사용하는 경우에도 dfs()의 호출 횟수는 V번
- 하지만, 인접 행렬을 사용할 때는 dfs() 내부에서 다른 모든 정점을 순회하며 두 정점 사이에 간선이 있는가를 확인해야 함
- 한 번의
dfs()실행에 O(V)의 시간이 든다 - 따라서 인접 행렬의 경우 전체 시간 복잡도는 O(V^2) 이다.
28.1.3 위상 정렬
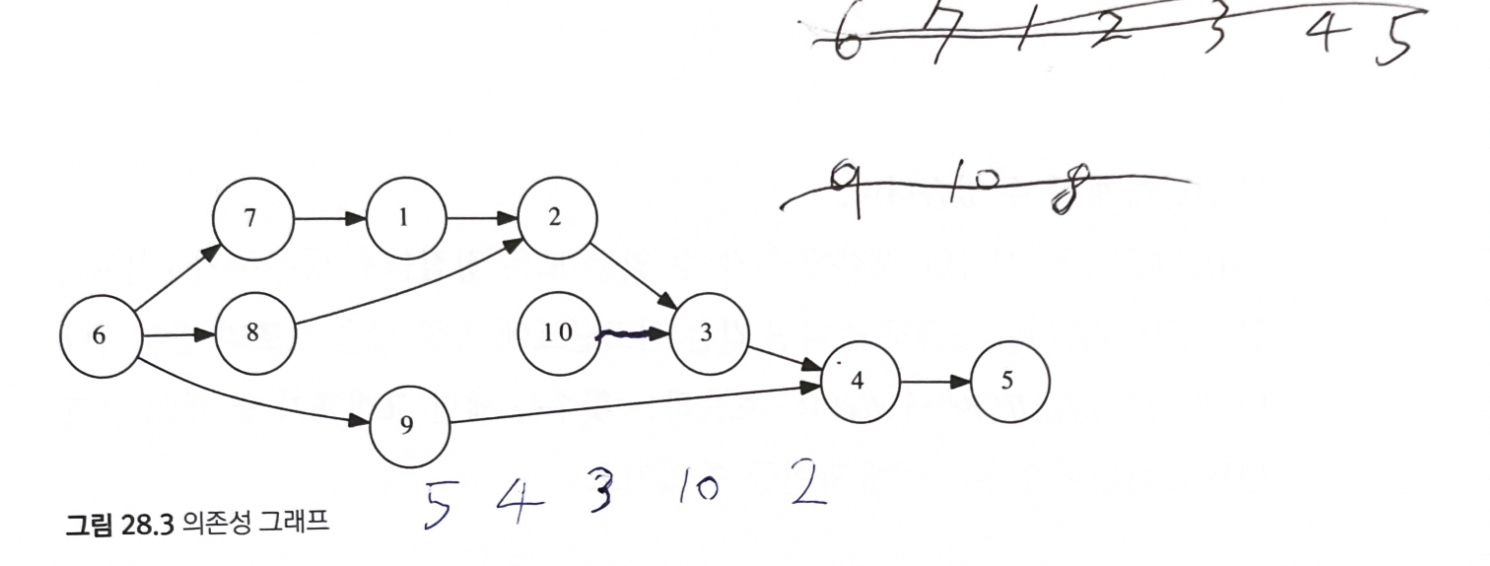
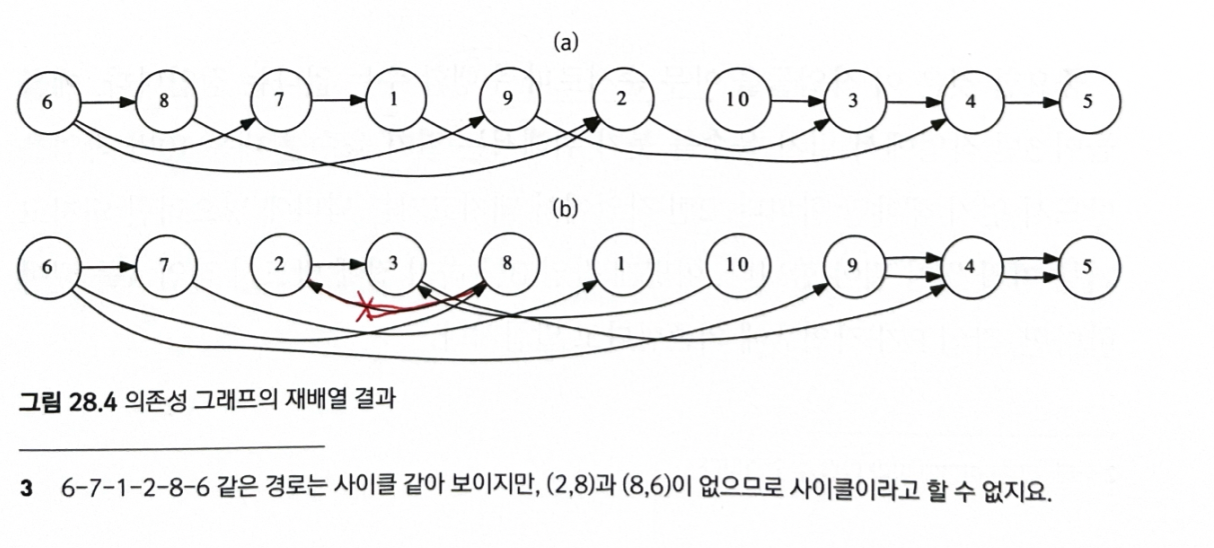

위상 정렬은 의존성이 있는 작업들이 주어질 때, 이들을 어떤 순서로 수행해야 하는지 계산해 준다.
- 위상 정렬의 결과는 항상 같지 않다. 구현 방법에 따라 달라진다.
각 작업들을 정점으로 표현하고, 작업 간의 의존 관계를 간선으로 표현한 방향 그래프를 의존성 그래프(dependency graph) 라고 한다.
- 의존성 그래프는 그래프에 사이클이 없다.
- 이 그래프는 사이클이 없는 방향 그래프(DAG) 가 된다.
의존성 그래프의 정점들을 일렬로 늘어놓고, 왼쪽에서부터 하나씩 수행한다고 하자
- 이때 모든 의존성이 만족되려면 모든 간선이 왼쪽에서 오른쪽으로 가야 한다.
- 이렇게 DAG의 정점을 배열하는 문제를 위상 정렬(topological sort) 이라고 한다.
위상 정렬을 구현하는 방법은
dfsAll()을 수행하며dfs()가 종료할 때마다 현재 정점의 번호를 기록하는 것dfsAll()이 종료한 뒤 기록된 순서를 뒺비으면 위상 정렬 결과를 얻을 수 있다.dfs()가 늦게 종료한 정점일 수록 정렬 결과의 앞에 온다.
dfs가 아닌 queue 를 이용한 위상 정렬
- 입력 차수, 진입 차수 (In-degree): 방향 그래프에서 한 정점으로 들어오는 간선의 수
- 출력 차수, 진출 차수 (Out-degree): 방향 그래프에서 한 정점에서 나가는 간선의 수
- 차수 (degree): 한 정점에서 인접한 간선의 수
| |
28.2, 28.3 고대어 사전, DICTIONARY, 난이도: 하
- 각 알파벳을 정점으로 표현, 한 알파벳이 다른 알파벳 앞에 와야 할 때 두 정점을 방향 간선으로 연결
- 우리가 원하는 알파벳 순서는 이 그래프를 위상 정렬 한 결과
- 인접한 단어들만 검사하더라도 그래프의 위상 정렬 결과는 모든 단어 쌍을 검사했을 때와 같다.
- 단어 A, B, C가 순서대로 등장한다면, (A, C)는 검사하지 않고, (A, B), (B, C)쌍 만 검사해도 된다.
- 그래프가 DAG면 빈 리스트 반환 / 아니면, 위상 정렬 결과 반환
28.7 이론적 배경과 응용
28.7.1 깊이 우선 탐색과 간선의 분류
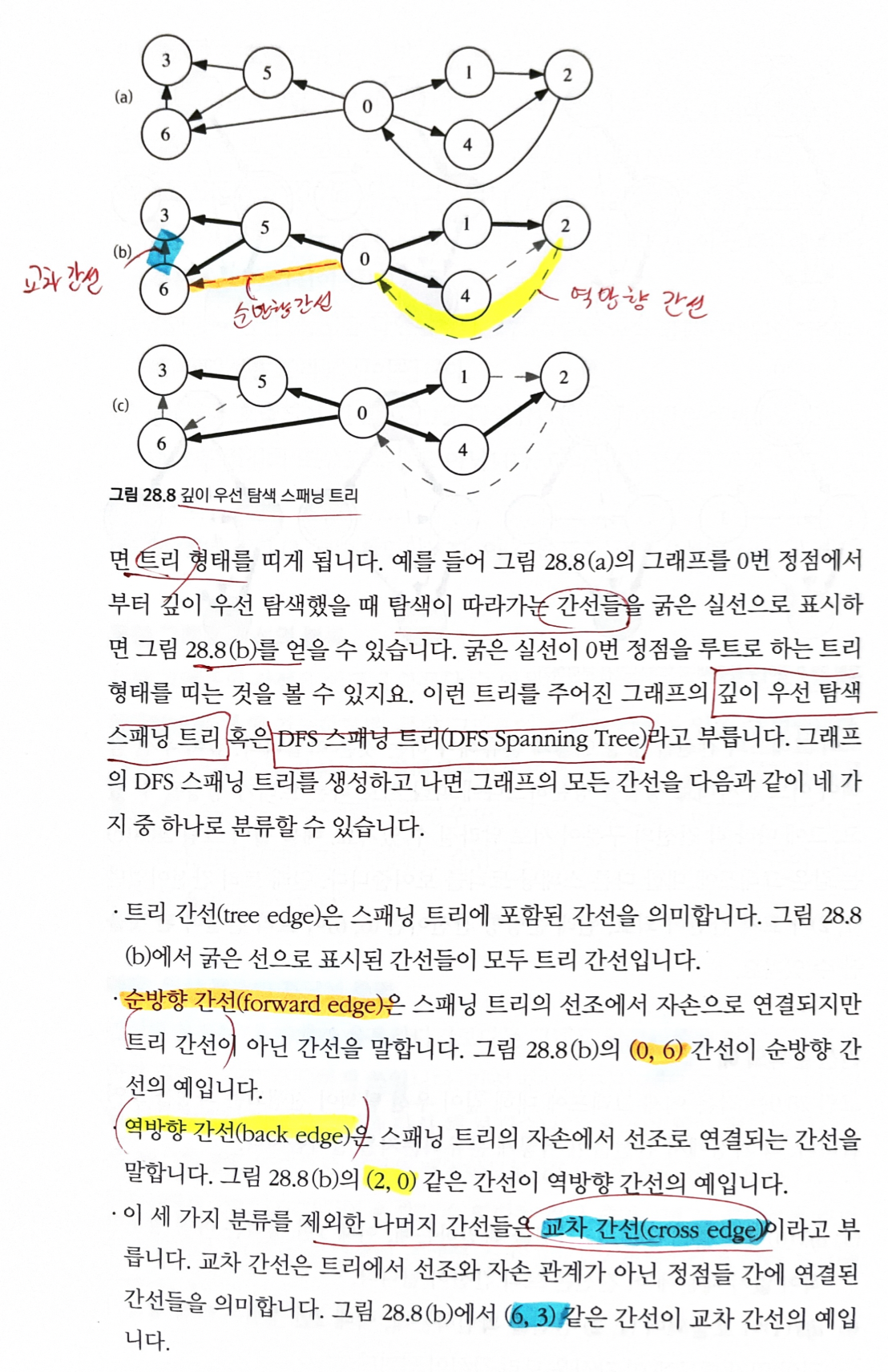
DFS를 수행하면, 그 과정에서 그래프의 모든 간선을 한 번씩 만나게 된다.
일부 간선은 처음 발견한 정점으로 따라가고, 나머지는 무시하게 된다.
- 그러나 이 간선들을 무시하지 않고 이들에 대한 정보를 수집하면 그래프의 구조에 대해 많은 것을 알 수 있다.
탐색이 따라가는 간선들만 모아 보면 트리 형태를 띠게 된다.
- 이런 트리를 주어진 그래프의
DFS 스패닝 트리(DFS Spanning Tree)라고 부른다.
- 이런 트리를 주어진 그래프의
DFS 스패닝 트리를 생성하면, 그래프 중 모든 간선을 네 가지 중 하나로 분류 할 수 있다.
간선 분류트리 간선(tree edge): 스패닝 트리에 포함된 간선
순방향 간선(forward edge): 스패닝 트리의 선조에서 자손으로 연겨되지만 트리 간선이 아닌 간선
역방향 간선(back edge): 스패닝 트리의 자손에서 선조로 연결되는 간선
교차 간선(cross edge): 1.2.3번 3가지 를 제외한 나머지 간선들,
- 교차 간선은 트리에서 선조와 자손 관계가 아닌 정점들 간에 연결된 간선들을 의미
그래프의 간선을 항상 4가지 중 하나로 분류해야 하는 것은 아니다.
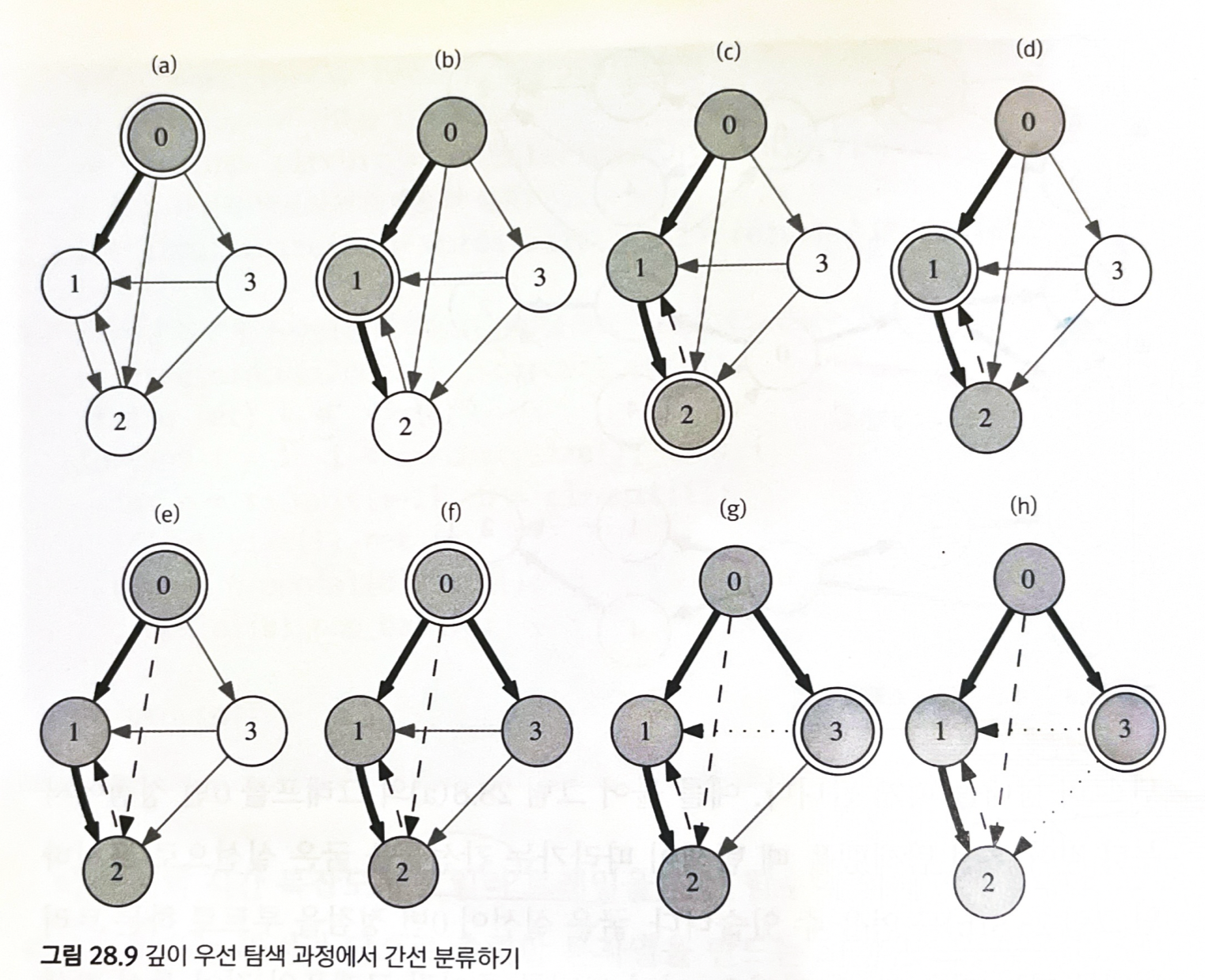
깊이 우선 탐색이 어느 순서대로 정점을 방문하느냐(실제 구현 방법)에 따라 서로 다른 트리가 생성될 수 있다.
무향 그래프 간선의 분류
- 무향 그래프는 교차 간선, 순방향, 역방향 간선의 구분이 있을 수 없다.
28.7.2 사이클 존재 여부 확인
간선 구분의 사용 예시, 방향 그래프에 사이클이 존재하는지 여부를 판정- ‘사이클의 존재 여부’는 ‘역방향 간선 존재 여부’ 와 동치
- 사이클에 포함된 정점 중 dfs 에서 처음 만나는 정점을 u라고 할 때,
- dfs(u)는 u에서 갈 수 있는 정점들을 모두 방문한 후에야 종료한다.
- 따라서, dfs는 사이클에서 u 이전에 있는 정점을 dfs(u)가 종료하기 전에 방문하게 되는데,
- 이 정점에서 u로가는 정점은 항상 역방향 간선이 된다.
28.7.3 간선 구분하는 방법
정점이 방문할 때 이 정점이 방문되었다는 사실 뿐만 아니라, 이 정점이 몇 번째로 발견되었는지도 동시에 기록
탐색 과정에서 각 정점을 몇 번째로 발견했는지를
배열 discovered[]에 저장- (u, v)가 순방향 간선 이려면, v는 u의 자손, 따라서 v는 u보다 더 늦게 발견되어야 한다.
- (u, v)가 역방향 간선 이려면 v는 u의 선조, 따라서 v는 u보다 일찍 발견되어야 한다.
- (u, v)가 교차 간선 이려면, dfs(v)가 종류한 후 dfs(u)가 호출되어야 한다. 따라서 v는 u보다 일찍 발견되어야 한다.
이처럼 발견 순서 정보를 이용하면 해당 간선이 순방향 간선인지를 알아낼 수 있다.
반면 v가 u보다 먼저 방문되었다면 v가 u의 부모인지 아닌지를 구분할 방법이 없다.
이때 구분하는 한 가지 방법은 dfs(v)가 종료햇는지를 확인하는 것
dfs(v)가 아직 종료하지 않았다면 v는 u의 선조 및 (u, v)는 역뱡향 간선
아니면 교차 간선
간선을 구분하는 깊이 우선 탐색 알고리즘 python 구현
| |
28.7.3 예제: 절단점 찾기 알고리즘
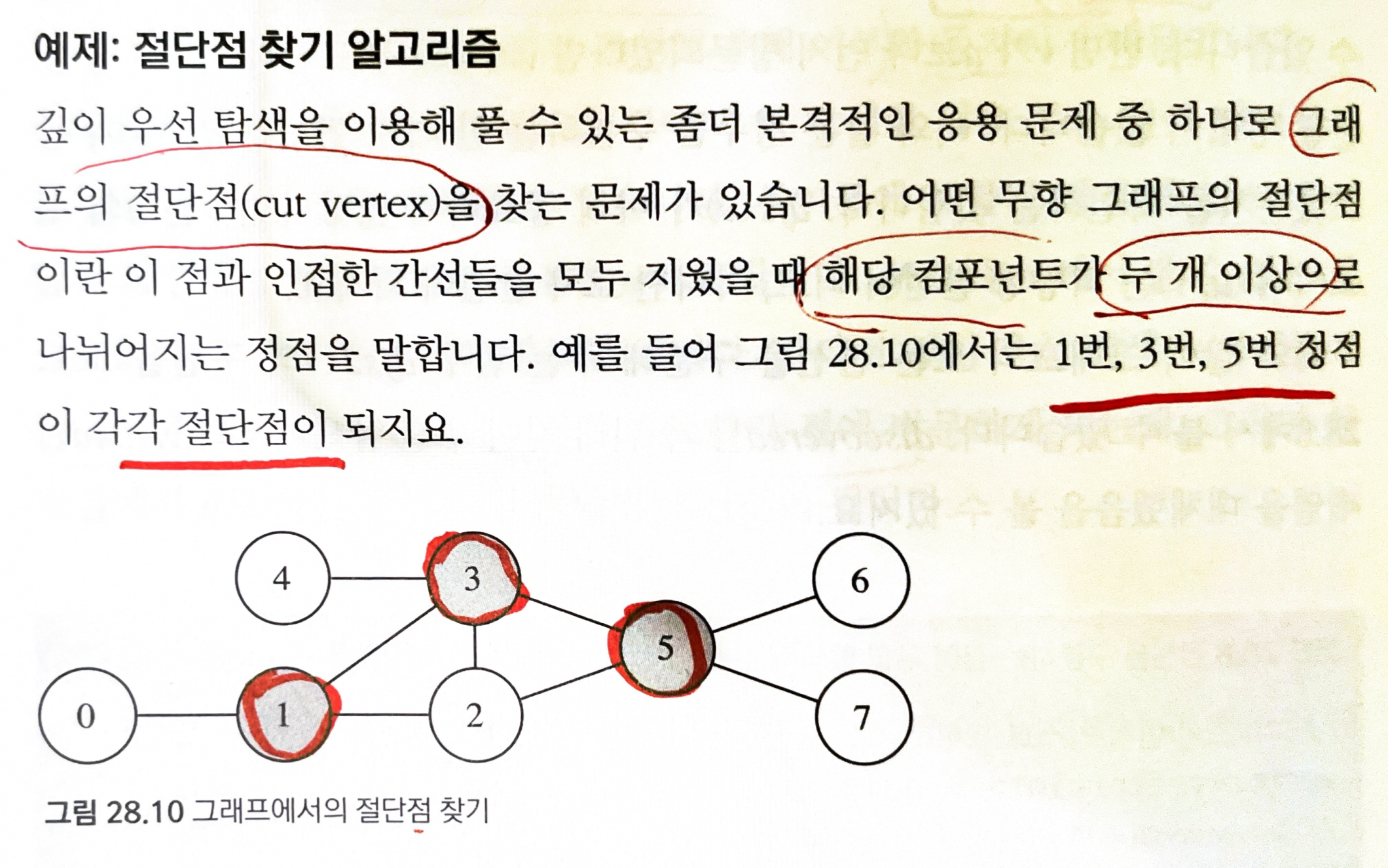
그래프의 절단점(cut vertex) 를 찾는 문제 - DFS를 이용해서 풀 수 있는 응용 문제 중 하나
무향 그래프의 절단점: 인접한 간선들을 모두 지웠을 때 해당 컴포넌트가 두 개 이상으로 나뉘어지는 정점을 말한다.
- 1, 3, 5번이 절단점이 된다.
어떤 정점이 절단점인지 확인하는 간단한 방법은 해당 정점을 그래프에서 삭제한 뒤, 컴포넌트의 개수가 이전보다 늘어났는지를 확인하는 것
모든 정점의 절단점 여부를 확인하려면, 깊이 우선 탐색을 V번 수행
그러나 탐색 과정에서 얻는 정보를 잘 이용하면 한 번의 깊이 우선 탐색만으로 그래프의 모든 절단점을 찾을 수 있다.
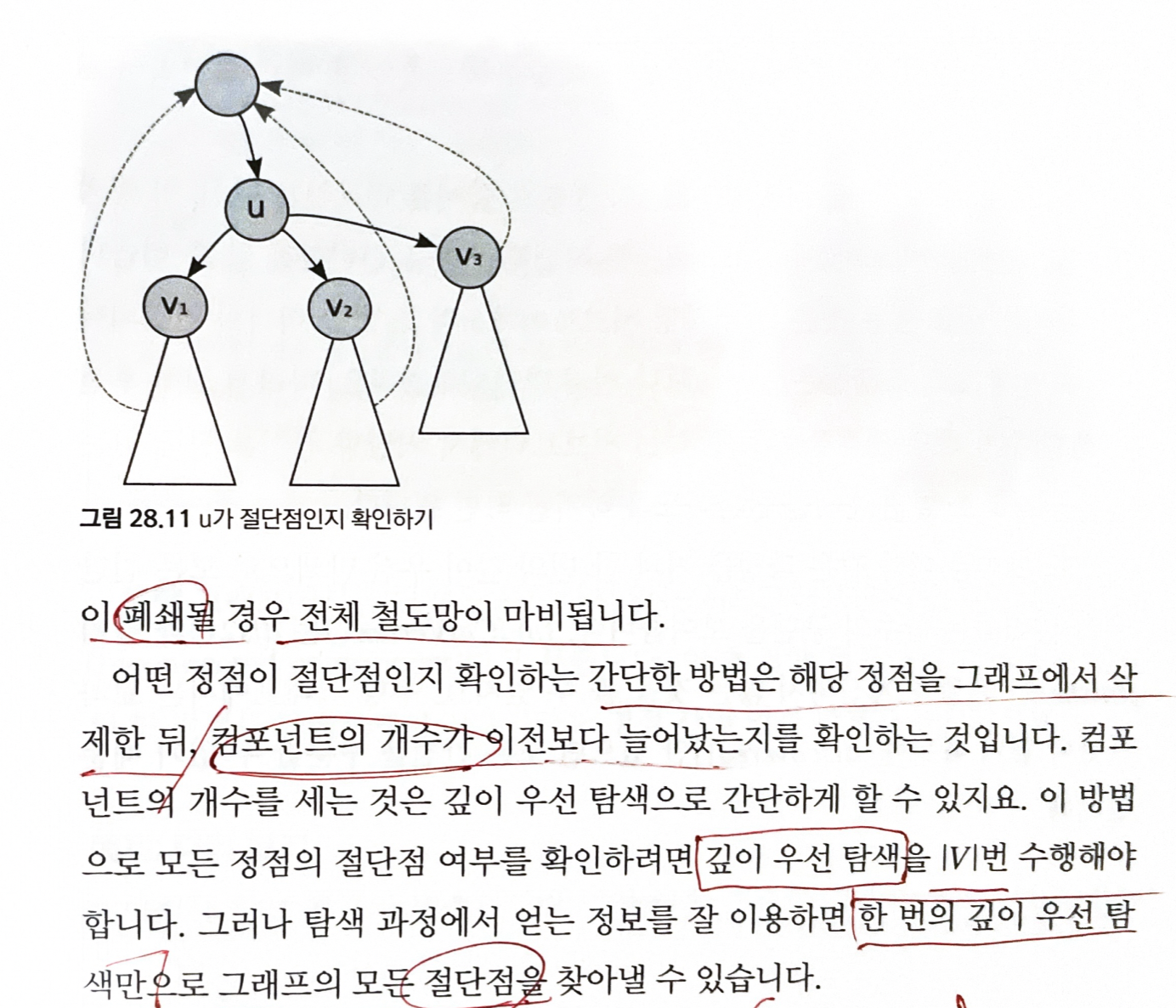
임의의 정점에서 DFS를 수행해 DFS 스패닝 트리를 얻는다.
어떤 정점 u 가 절단점인지 알 수 있는 방법
- 그래프가 쪼개지지 않는 유일한 경우는 그림 처럼 u의 선조와 자손들이 전부 역뱡향 간선으로 연결되어 있을 때 뿐이다.
- 이것을 확인하는 방법은 DFS를 수행하는 dfs2()가 각 정점을 루트로 하는 서브트레엇 역뱡향 간선을 통해 갈 수 있는 정점의 최소 깊이를 반환하도록 하는 것
- 만약 u의 자손들이 모두 역방향 간선을 통해 u의 선조로 올라갈 수 있다면 u는 절단점이 아니다.
u가 스패닝 트리의 루트라서 선조가 없다면 어떻게 될까?
- u는 무조건 절단점이라고 생각하기 쉽지만, 간과하기 쉬운 예외가 있다.
- 바로 자손이 하나도 없거나 하나밖에 없는 경우다.
- 이 경우 u가 없어져도 그래프는 쪼개지지 않는다.
- 따라서 u가 루트인 경우 둘 이상의 자손을 가질 때만 절단점이 된다.
실제로 이 알고리즘을 구현할 때는 각 정점의 깊이를 비굔하는 대신, 각 정점의 발견 순서를 비교하는 형태로 코드를 작성해 간단히 구현할 수 있다.
- 알고 싶은 것은 해당 서브트리가 u의 조상 중 하나와 연결되어 있는지인데, u의 조상들은 항상 u보다 먼저 발견된다.
- 따라서, 깊이 우선 탐색 함수가 해당 정점을 루트로 하는 서브트리에서 역방향 간선을 통해 닿는 정점들의 최소 발견 순서를 반환하면 된다.
무향 그래프에서 절단점을 찾는 알고리즘 python 구현
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32N = 10 discovered = [-1 for _ in range(N)] # i번 정점의 발견 순서 finished = [False for _ in range(N)] # dfs가 종료했으면 True 아니면 False isCutVertex = [False for _ in range(N)] # True면 절단점 graph = [[] for _ in range(N)] result = dict() counter = 0 # 지금까지 발견한 정점의 수 # node를 루트로 하는 서브트리에 있는 절단점들을 찾는다 # 반환 값은 해당 서브트리에서 역방향 간선으로 갈 수 있는 정점 중, 가장 일찍 발견된 정점의 발견 시점 # 처음 호출 할때는 isRoot = True 로 둔다. def findCutVertex(node, isRoot): global counter counter += 1 discovered[node] = counter ret = discovered[node] children = 0 nxtLst = graph[node] for nxt in nxtLst: if discovered[nxt] == -1: children += 1 # 루트인 경우의 절단점 판정을 위해 자손 서브트리의 개수를 샌다. subTreeMaxNode = findCutVertex(nxt, False) # 서브 트리에서 갈 수 있는 가장 높은 정점의 번호 ret = min(ret, subTreeMaxNode) if not isRoot and subTreeMaxNode >= discovered[node]: # 그 노드가 자기 자신의 이하에 있다면 현재 위치는 절단점이다. isCutVertex[node] = True else: ret = min(ret, discovered[nxt]) if isRoot: isCutVertex[node] = (children >= 2) # 루트인 경우 절단점 판정은 서브트리의 개수 return ret무향 그래프에서 절단점을 포함하지 않는 서브 그래프를
이중 결합 컴포넌트(biconnected component)라고 부른다.
Reference
- 프로그래밍 대회에서 배우는 알고리즘 문제 해결 전략 (구종만, 인사이트)
- https://www.algospot.com/