코틀린 Reflection 설명
Reflection은 프로그램 실행 중에 코드의 구조 (클래스, 함수, 프로퍼티 등)를 분석하고 조작할 수 있는 기능입니다.
코틀린에서는 kotlin-reflect 라이브러리를 통해 Reflection을 사용할 수 있습니다.
Reflection의 주요 기능:
- 클래스 정보 조회: 클래스 이름, 상위 클래스, 인터페이스, 생성자, 메서드, 프로퍼티 등 클래스의 구조 정보를 가져올 수 있습니다.
- 함수 호출: 함수 객체를 가져와 동적으로 함수를 호출하고 결과를 얻을 수 있습니다.
- 프로퍼티 접근: 프로퍼티 객체를 가져와 값을 읽거나 변경할 수 있습니다.
- 생성자 호출: 생성자 객체를 가져와 동적으로 객체를 생성할 수 있습니다.
코틀린 Reflection 사용 방법:
- 의존성 추가:
build.gradle파일에kotlin-reflect라이브러리 의존성을 추가합니다. - 클래스 참조 가져오기:
::class연산자를 사용하여KClass객체를 가져옵니다.
| |
- 클래스 정보 조회:
KClass객체의 메서드를 사용하여 클래스 정보를 조회합니다.
| |
- 함수 호출:
KFunction객체의call()또는callBy()메서드를 사용하여 함수를 호출합니다.
| |
- 프로퍼티 접근:
KProperty객체의getter또는setter를 사용하여 프로퍼티 값을 읽거나 변경합니다.
| |
Reflection 사용 시 주의 사항:
성능 저하: Reflection은 일반적인 메서드 호출이나 프로퍼티 접근보다 성능이 떨어질 수 있습니다.
유지보수 어려움: Reflection을 사용하면 컴파일 시점에 타입 검사가 이루어지지 않으므로, 런타임 오류 발생 가능성이 높아지고 코드의 유지보수가 어려워질 수 있습니다.
보안 문제: Reflection을 통해 private 멤버에 접근할 수 있으므로, 보안에 유의해야 합니다.
Reflection 사용 예시:
- JSON 파싱 라이브러리: Gson, Moshi 등의 JSON 파싱 라이브러리는 Reflection을 사용하여 JSON 데이터를 객체로 변환합니다.
- 의존성 주입 프레임워크: Dagger, Hilt 등의 의존성 주입 프레임워크는 Reflection을 사용하여 의존성을 주입합니다.
- 테스트 프레임워크: Mockito 등의 테스트 프레임워크는 Reflection을 사용하여 Mock 객체를 생성하고 메서드 호출을 가로챕니다.
Kotlin 1.9에서 Enum.entries 설명
Kotlin 1.9.0부터 Enum 클래스에 entries 프로퍼티가 추가되었습니다.
이는 기존의 values() 함수의 대안으로, 더 안전하고 효율적인 방식으로 Enum 상수 목록을 가져올 수 있도록 합니다.
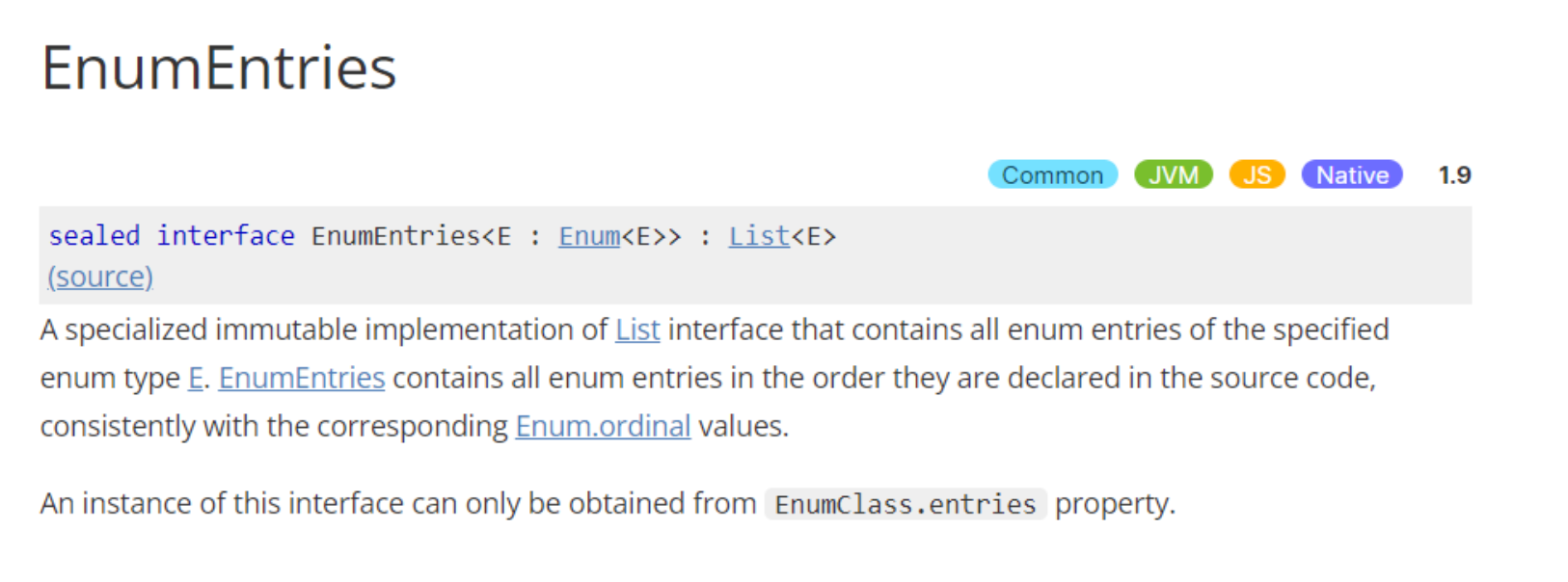
Enum.entries의 장점:
불변성 (Immutability):
entries는 Enum 상수 목록의 복사본을 반환하지 않고, 원본 목록에 대한 참조를 반환합니다. 따라서 실수로 목록을 수정하여 예기치 않은 결과를 초래하는 것을 방지합니다.성능 향상:
values()함수는 매번 호출될 때마다 새로운 배열(Array) 을 생성하여 반환하는 반면,entries는 한 번만 생성된 목록을 반환하므로 메모리 사용량을 줄이고 성능을 향상시킵니다.
List 인터페이스 지원:
entries는List인터페이스를 구현하므로,filter,map,forEach등 다양한 List 관련 함수를 활용할 수 있습니다.
values()는 모든 호출 마다 Mutable Array 복사본을 생성해서 반환하기 때문에, API 본질적 설계 버그입니다.
이는 values()이 반환한 Array 값을 악의적인 의도로 변경하거나 배열을 조작하려는 개발자의 실수로 이어질 수 있습니다.
코틀린 코드 컴파일 및 빌드
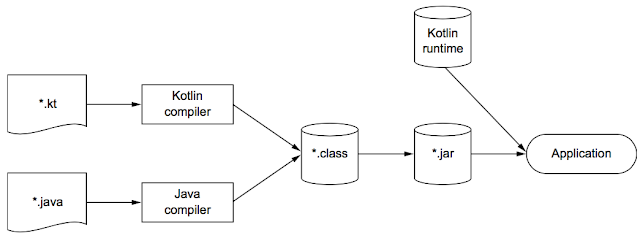
코틀린 컴파일러는 자바 컴파일러가 자바 소스코드를 컴파일할 때와 마찬가지로코틀린 소스코드(.kt)를 분석해서.class파일을 만들어낸다.- 만들어진
.class파일은 개발 중인 애플리케이션의 유형에 맞는 표준패키징과정을 거쳐 실행될 수 있다.
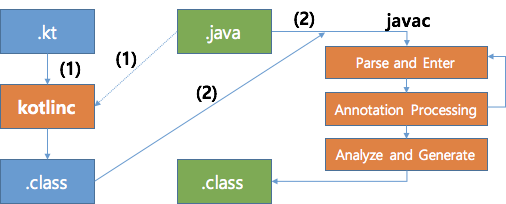
- Java 코드와 Kotlin 코드의 빌드 과정은 다음과 같은 순서로 이루어진다.
- 코틀린 컴파일러가 코틀린 코드를 컴파일해
.class파일을 생성한다. 이 과정에서 코틀린 코드가 참조하는 Java 코드가 함께 로딩되어 사용된다. - Java 컴파일러가 Java 코드를 컴파일해
.class파일을 생성한다. 이때 이미 코틀린이 컴파일한.class파일의 경로를 클래스 패스에 추가해 컴파일한다.- 코틀린 컴파일러로 컴파일한 코드는
코틀린 런타임 라이브러리(kotlin runtime library)에 의존한다. 코틀린 런타임 라이브러리:코틀린 자체 표준 라이브러리 클래스+코틀린에서 자바 API의 기능을 확장한 내용- 코틀린으로 컴파일한 애플리케이션을 배포할때는
코틀린 런타임 라이브러리도 함께 배포해야 한다. - 프로젝트를 컴파일하기 위해
메이븐(Maven)과그레이(Gradle),앤트(Ant)등의 빌드 시스템을 사용 - 빌드 시스템은 모두 코틀린과 자바가 코드베이스에 함께 들어있는 혼합 언어 프로젝트를 지원할 수 있다
메이븐(Maven)과그레이(Gradle)들은 애플리케이션을 패키지할 때 알아서코틀린 런타임 라이브러리을 포함시켜준다.
- 코틀린 컴파일러로 컴파일한 코드는
Map
Kotlin의 Map 인터페이스는 구현 방법에 따라 다르며, 그 자체는 특정 자료구조(예: 해시 테이블)에 의존하지 않습니다.
Map 은 단지 키-값 쌍을 관리하는 기능을 정의한 인터페이스일 뿐, 이를 어떻게 구현할지는 구체적인 구현체에 따라 달라집니다.
1. Map은 인터페이스
Map은 키-값 쌍을 관리하는 추상적인 개념을 정의한 인터페이스입니다.Map인터페이스를 구현하는 여러 클래스들이 존재하며, 이 클래스들이 각기 다른 방식으로 내부 동작을 처리합니다.- 예를 들어,
Map인터페이스를 구현한 클래스 중에는 해시 테이블 기반의HashMap, 순서를 유지하는LinkedHashMap, 정렬된 맵을 제공하는TreeMap등이 있습니다.
2. HashMap은 해시 테이블 기반
HashMap은Map인터페이스의 구현체 중 하나로, 해시 테이블을 사용하여 데이터를 저장하고 관리합니다. 이는 빠른 조회와 삽입을 위해 해시 함수를 사용하며, 평균적으로 O(1)의 성능을 제공합니다.- 따라서,
HashMap은 해시 테이블 기반의 맵이 맞습니다.
3. 다른 Map 구현체들
Map 인터페이스는 여러 가지 구현체가 있으며, 각 구현체는 다른 방식으로 데이터를 저장하고 관리합니다.
mapOf(): 내부적으로java.util.Collections.singletonMap()을 사용, 불변인 map 객체를 반환mutableMapOf():내부적으로LinkedHashMap을 사용
| |
주요 Map 구현체:
HashMap:- 해시 테이블 기반으로, 키의 순서를 유지하지 않으며 빠른 접근 성능(O(1))을 제공합니다.
LinkedHashMap:- 해시 테이블을 기반으로 하지만, 삽입된 순서를 유지합니다. 따라서 데이터를 삽입한 순서대로 접근할 수 있습니다.
TreeMap(자바):1 2 3 4val treeMap: TreeMap<String, Int> = TreeMap<String, Int>().apply { put("b", 2) put("a", 1) }
코틀린에서 pass By 방법
Kotlin은 기본적으로 “값에 의한 전달” (pass by value) 를 사용합니다.
그러나 참조 타입을 사용할 때는, 참조의 값을 전달하는 방식으로 작동하기 때문에, 참조에 의한 전달(pass by reference) 와 비슷하게 동작할 수 있습니다.
자세한 설명:
기본 타입 (Primitive Types):
Int,Float,Double,Boolean과 같은 기본 데이터 타입은 값에 의한 전달 (pass by value) 로 동작합니다. 즉, 함수에 값을 전달하면 복사본이 전달되며, 함수 내에서 값을 변경하더라도 원본에는 영향을 미치지 않습니다.예시:
1 2 3 4 5 6 7 8 9 10fun modifyValue(x: Int) { // x는 복사된 값이므로, 이 함수 내에서 변경되어도 원래 값에는 영향을 주지 않음 x = x + 1 } fun main() { var a = 10 modifyValue(a) println(a) // 출력: 10 (변경되지 않음) }참조 타입 (Reference Types): Kotlin의 클래스 객체나 배열, 리스트 등 참조 타입의 경우, 값에 의한 전달이지만 참조의 값을 전달합니다. 즉, 객체 자체는 전달된 참조를 통해 접근할 수 있기 때문에, 객체의 속성을 변경할 수 있습니다. 하지만, 참조 자체를 변경하면, 그 변경은 함수 외부에 영향을 미치지 않습니다.
예시:
1 2 3 4 5 6 7 8 9 10 11 12data class Person(var name: String) fun modifyPerson(person: Person) { // person은 참조의 값이 전달되므로, 객체의 속성을 변경할 수 있음 person.name = "Modified" } fun main() { val person = Person("Original") modifyPerson(person) println(person.name) // 출력: Modified (속성이 변경됨) }- 이 경우, 객체의 속성은 함수 내에서
- 변경할 수 있지만, 참조 자체를 다른 객체로 바꾸는 것은 함수 외부에 영향을 주지 않습니다.
요약:
- 기본 타입 (Primitive types): 값에 의한 전달 (
pass by value)로 동작. - 참조 타입 (Reference types): 참조의 값을 전달하지만, 객체의 속성을 변경할 수 있기 때문에 참조에 의한 전달처럼 동작할 수 있음.
실제로 Kotlin은 값에 의한 전달만 존재합니다. 다만 참조 타입을 함수에 전달할 때, 그 참조된 객체의 속성은 함수 내에서 변경될 수 있습니다.
참고
result.add(combination.toList()) 에서 toList() 로 깊은 복사를 하지 않으면,
result 가 [[], [], []] 가 되어 버린다.
이유는 combination를 result에 추가할 때 참조의 값를 그대로 넘겨주기 때문입니다.
Kotlin의 MutableList는 참조 타입이므로, combination가 변경되면 result에 있는 리스트도 함께 변경됩니다.
따라서 나중에 값을 변경할 때 result에 추가된 값도 동일하게 변경되는 문제가 발생합니다.
| |
Array 에서는?
IntArray는 Kotlin에서 기본 타입 배열(primitive array) 로, Int 타입의 값들을 저장하는 배열입니다.
이 경우도 마찬가지로, Kotlin은 값에 의한 전달(pass by value) 를 사용합니다. 하지만, IntArray 자체는 참조 타입으로 동작하므로, 참조의 값이 전달됩니다.
따라서, 배열 내부의 요소는 함수에서 수정할 수 있지만, 배열 자체를 새로운 배열로 변경하는 것은 함수 외부에 영향을 미치지 않습니다.
예시 1: 배열의 요소를 변경할 때
| |
- 배열의 참조가 전달되므로, 배열의 내부 값을 수정할 수 있습니다.
- 위의 경우, 함수 내에서 배열의 첫 번째 요소가 변경되었고, 원래 배열(
nums)도 이 변경 사항을 반영합니다.
예시 2: 배열 자체를 새로 할당할 때
| |
- 배열 자체를 새로운 배열로 할당하려고 하면, 함수 내에서만 새로운 배열이 할당되고, 원본 배열은 변경되지 않습니다.
- 이는 배열의 참조 값이 복사되어 전달되기 때문에, 원본 배열의 참조 자체는 변경되지 않는 것입니다.
요약:
- 배열의 요소는 함수 내에서 변경할 수 있으며, 이 변경 사항은 함수 외부에도 영향을 미칩니다. 이는 배열의 참조가 전달되기 때문입니다.
- 하지만 배열 자체를 새로운 배열로 할당하는 것은 함수 내에서만 영향을 미치며, 함수 외부의 배열에는 영향을 주지 않습니다.
따라서, IntArray의 경우에도 참조의 값이 전달되므로, 배열의 내부 값을 수정할 수는 있지만, 참조 자체는 변경되지 않습니다.
IntArray vs Array<Int>
Kotlin에서 IntArray와 Array<Int>는 모두 정수형 배열을 나타내지만,
둘 사이에는 중요한 차이점이 있습니다. 이 차이는 메모리 효율성과 타입에 대한 처리 방식에서 비롯됩니다.
1. IntArray
- Primitive 타입 배열로, 메모리 효율이 뛰어납니다.
- 배열의 요소가
int타입의 원시값으로 저장되므로, 박싱(boxing) 이 발생하지 않습니다. - Kotlin에서 제공하는 원시 배열 중 하나로, 자바의 primitive 배열(
int[])과 대응됩니다. - 주로 성능이 중요한 상황에서 사용됩니다.
| |
이 경우, 메모리에는 각 요소가 원시 정수로 저장됩니다.
IntArray는 자바의int[]와 대응
2. Array<Int>
- 참조 타입 배열입니다. 배열의 각 요소가 객체(
Integer)로 저장되며, 박싱(boxing) 이 발생합니다. - 즉, 배열 요소들이 기본적으로 객체로 처리되므로, 추가적인 메모리 사용이 있습니다.
Array<Int>는 제네릭 배열이므로 Kotlin의Array<T>와 대응됩니다.
| |
각 요소는 객체(Integer) 로 저장되므로, 박싱이 발생합니다.
Array<Int>는Integer[]와 대응
3. 차이점 요약
| 속성 | IntArray | Array<Int> |
|---|---|---|
| 타입 | Primitive 타입 (int) | 참조 타입 (Integer) |
| 메모리 효율성 | 더 효율적 (박싱 없음) | 덜 효율적 (박싱 발생) |
| 자바 대응 | int[] | Integer[] |
| 주 사용 상황 | 성능이 중요한 경우 | 제네릭 배열이 필요한 경우 |
| 함수 지원 | IntArray에 맞는 특수 함수 제공 | Array<T>에 맞는 일반 함수 제공 |
4. 어떤 경우에 사용하나요?
IntArray: 성능과 메모리 사용이 중요한 경우, 예를 들어 대규모 데이터를 처리하거나, 원시 배열과의 호환성이 중요한 경우.Array<Int>: 일반적인 제네릭 배열이 필요한 경우 또는 참조 타입을 사용해야 하는 경우.
5. 변환 방법
두 배열 간의 변환이 필요한 경우 다음과 같이 처리할 수 있습니다:
IntArray->Array<Int>변환:1 2val intArray = IntArray(5) { it } val arrayInt: Array<Int> = intArray.toTypedArray()Array<Int>->IntArray변환:1 2val arrayInt = arrayOf(1, 2, 3, 4, 5) val intArray: IntArray = arrayInt.toIntArray()
Map의 반복 처리
Kotlin에서 Map 이 Iterable 인터페이스를 직접 구현하지 않으면서도 반복 처리가 가능한 이유는 Map 자체가 entries, keys, 그리고 values 라는 컬렉션 뷰(Collection Views) 를 제공하기 때문입니다.
이 각각의 뷰는 Set 또는 Collection 으로 표현되며, 이들이 Iterable 을 구현하고 있어 for 루프나 forEach와 같은 반복 처리가 가능해집니다.
구체적인 설명:
1. Map 자체는 Iterable을 구현하지 않음
Map인터페이스 자체는Iterable을 직접 구현하지 않습니다. 즉,Map자체는 키와 값의 쌍을 저장하는 고유한 자료구조로, 단순히 한 방향으로 순차적으로 탐색되는 데이터 구조가 아닙니다.Map의key,value,entry들은 내부적으로 별도의 컬렉션(Set, Collection 등) 을 통해 구현됩니다.
2. entries, keys, values 컬렉션
Map에서 제공하는 세 가지 주요 컬렉션 뷰는 모두 반복 처리를 위한 Iterable을 구현하고 있습니다. 이 컬렉션들이 바로 Map을 반복 처리할 수 있게 도와줍니다.
entries:Map의 모든 키-값 쌍을 나타내며, 이는Set<Map.Entry<K, V>>로 반환됩니다.Set은Iterable을 구현하므로, 이entries컬렉션을 통해Map의 각 엔트리를 순회할 수 있습니다.keys:Map의 모든 키를 포함한 컬렉션이며, 이는Set<K>로 반환됩니다. 역시Set이Iterable을 구현하므로,keys를 통해 모든 키를 순회할 수 있습니다.values:Map의 모든 값을 포함한 컬렉션이며, 이는Collection<V>로 반환됩니다.Collection은Iterable을 구현하므로,values를 순회할 수 있습니다.
함수 타입과 함수형 인터페이스
Kotlin은 자바와 달리 람다 표현식을 사용할 때 함수 타입을 지원합니다.
자바는 함수 타입을 지원하지 않기 때문에, 람다를 넘기려면 함수형 인터페이스를 사용해야 합니다.
그러나 Kotlin에서는 굳이 함수형 인터페이스를 만들 필요 없이, 함수 타입을 직접 인자로 사용할 수 있기 때문에, 인터페이스에 의존하는 방식이 필요하지 않습니다.
1. Kotlin의 함수 타입
Kotlin에서는 함수 타입을 파라미터로 정의할 수 있습니다. 예를 들어, (Int) -> Unit과 같은 함수 타입을 직접적으로 파라미터로 사용해 함수를 작성할 수 있습니다.
함수 타입을 인자로 사용하는 예시:
| |
이 코드는 정상적으로 작동하며, executeAction 함수는 함수 타입(() -> Unit) 을 인자로 받습니다. Kotlin에서는 이처럼 인터페이스 대신 함수 타입을 직접 사용할 수 있습니다.
2. 함수형 인터페이스와의 차이점
Kotlin에서는 fun interface 키워드를 사용하여 자바의 함수형 인터페이스와 유사한 방식을 사용할 수 있습니다. 하지만 기본적으로 함수 타입을 사용할 수 있기 때문에, 대부분의 경우 함수형 인터페이스보다 함수 타입을 더 선호합니다.
자바 스타일의 함수형 인터페이스 사용:
| |
위 코드는 함수형 인터페이스를 사용하여 인자로 넘기는 예시입니다. fun interface로 정의된 인터페이스는 단일 추상 메서드(SAM) 를 가지기 때문에 람다로 구현할 수 있습니다.
하지만 이 방식은 자바와의 상호 운용성(interop)을 위해 사용되며, 일반적으로 Kotlin에서는 함수 타입을 사용하는 것이 더 자연스럽습니다.
3. 요약
Kotlin에서 하나의 추상 메서드만 있는 인터페이스를 인자로 받는 함수에 람다를 넘기려면, fun interface 를 명시적으로 선언해야 합니다. 그렇지 않으면, Kotlin은 그 인터페이스를 함수 타입으로 간주하지 않기 때문에 람다 표현식을 바로 전달할 수 없고 오류가 발생합니다.
하지만 Kotlin에서는 함수형 인터페이스 없이도 함수 타입을 바로 사용할 수 있으므로, 함수 타입을 파라미터로 사용할 수 있는 경우에는 인터페이스를 굳이 정의하지 않아도 됩니다. 이는 Kotlin의 함수 타입 지원 덕분에 발생하는 차이점입니다.
reified 상세
Kotlin에서 reified 키워드는 제네릭 타입을 런타임에 구체화(reify) 할 수 있게 해줍니다.
보통 제네릭 타입은 런타임에 타입 정보가 소거(erase) 되지만, reified를 사용하면 타입 정보를 런타임에도 유지할 수 있어, 제네릭 타입에 대한 타입 검사나 타입 캐스팅을 런타임에 수행할 수 있게 됩니다.
reified가 필요할 때:
- 제네릭 타입 소거(Type Erasure) 문제:
- 일반적으로 제네릭 타입은 런타임에 소거됩니다. 즉, 제네릭 타입 정보는 컴파일 시에는 존재하지만, 런타임에서는 해당 정보가 제거되어 타입 정보를 알 수 없습니다.
- 예를 들어, 제네릭 함수에서
T::class또는T is SomeClass와 같은 타입 체크나 타입 캐스팅을 하려면reified가 필요합니다.
예시: reified 사용
| |
설명:
inline함수:reified키워드는 인라인 함수에서만 사용할 수 있습니다. 인라인 함수는 컴파일 시 함수 호출을 본문으로 대체하므로, 제네릭 타입이 소거되지 않고 타입 정보가 유지됩니다.reified키워드: 제네릭 타입T를 구체화(reify) 하여, 런타임에서도 해당 타입에 접근할 수 있습니다. 이로 인해T is String과 같은 타입 검사를 런타임에서 할 수 있습니다.
reified 없는 경우: 컴파일 오류 발생
| |
위 코드에서 제네릭 타입 T는 타입 소거가 발생하기 때문에, 런타임에는 T의 타입 정보를 알 수 없습니다. 그래서 value is T와 같은 코드는 컴파일 오류가 발생합니다.
reified를 사용한 응용:
- 제네릭 타입을 클래스 타입으로 변환 (
T::class사용):
| |
- 제네릭 타입의 인스턴스 생성:
| |
- 제네릭 타입 캐스팅:
| |
결론:
reified는 제네릭 타입을 구체화하여 런타임에 타입 정보를 유지할 수 있게 해줍니다.- 이를 통해 타입 검사, 타입 캐스팅, 타입 관련 함수(T::class) 를 사용할 수 있습니다.
reified는 인라인 함수와 함께 사용해야 하며, 일반 제네릭 함수에서는 사용할 수 없습니다.
runCatching
runCatching은 Kotlin에서 예외 처리와 관련된 함수로, 코드 블록을 실행하고 그 결과나 예외를 Result 객체로 반환한다.
이 함수는 코드에서 발생할 수 있는 예외를 간결하게 처리할 수 있도록 도와준다.
runCatching은 함수 블록을 실행한 후 성공했을 경우에는 Result.success로, 예외가 발생했을 경우에는 Result.failure로 감싼 결과를 반환한다.
이를 통해 예외를 명시적으로 던지지 않고도 안전하게 처리할 수 있다.
사용법
| |
반환되는 Result 객체
- 성공 (
Result.success): 블록이 성공적으로 실행되면 결과 값을 포함한Result.success객체를 반환한다. - 실패 (
Result.failure): 블록에서 예외가 발생하면 해당 예외를 포함한Result.failure객체를 반환한다.
주요 함수
isSuccess: 실행이 성공했는지 여부를 확인.isFailure: 예외가 발생했는지 여부를 확인.getOrNull(): 성공한 경우 결과 값을 반환하고, 실패한 경우null을 반환.exceptionOrNull(): 실패한 경우 예외를 반환하고, 성공한 경우null을 반환.getOrElse(defaultValue): 성공하면 값을 반환하고, 실패하면 기본 값을 반환 또는 다른 예외 처리를 적용onSuccess(action): 성공했을 때 실행할 동작을 지정.onFailure(action): 실패했을 때 실행할 동작을 지정.
예시
성공 예시
| |
실패 예시
| |
getOrElse로 기본 값 처리
| |
onSuccess와 onFailure
runCatching에서 반환된 Result 객체는 onSuccess와 onFailure를 이용해 성공과 실패에 대해 각각의 후속 작업을 정의할 수 있다.
| |
장점
- 코드가 간결해지고 가독성이 향상된다.
- 함수형 프로그래밍 스타일과 잘 맞아
onSuccess,onFailure등의 체이닝이 가능하다. - 명시적인 예외 처리와
Result객체를 활용한 구체적인 예외 처리 로직을 적용할 수 있다.
단점
- 복잡한 예외 처리에 적합하지 않다.
- 디버깅이 어려울 수 있고, 성능 오버헤드가 발생할 수 있다.
- 익숙하지 않은 경우 직관적으로 이해하기 어려울 수 있다.