1.1 SQL을 직접 다룰 때 발생하는 문제점
1.1.1 반복
- 데이터베이스는 객체 구조와는 다른 데이터 중심의 구조를 가짐, 개발자가 객체지향 App과 DB 중간에서 SQL과 JDBC API를 사용해서 변환 작업을 해야 함
- 테이블에 비례해서 SQL를 개발자가 작성해야 함, 지루하고 반복적인 일
1.1.2 SQL에 의존적인 개발
- App에서 문제가 생기면, DAO를 열어서 어떤 SQL이 실행되는지 확인해야 함, 계층 분할이 어려움
- 어떤 SQL이 실행되고 어떤 객체들이 함께 조회되는지 일일이 확인해야 함. 엔티티를 신뢰할 수 없음
1.1.3 JPA와 문제 해결
- JPA가 제공하는 API로, JPA가 자동으로 생성하는 적절한 SQL로 SQL을 직접 다룰 때 발생하는 문제점를 해결
1.2 패러다임의 불일치
OOP는 추상화, 캡슐화, 정보은닉, 상속, 다형성 등 시스템의 복잡성을 제어할 수 있는 다양한 장치들을 제공한다.
비즈니스 요구사항을 정의한 도메인 모델도/객체로 모델링하면 객체지향 언어가 가진 장점들을 활용할 수 있다.
문제는 이렇게 정의한 도메인 모델을저장할 때발생한다.
- 예를 들어, 특정 유저가 시스템에 회원 가입하면 회원이라는 객체 인스턴스를 생성한 후에 이 객체를 메모리가 아닌 어딘가에 영구 보관해야 한다.
RDBMS에 객체를 저장하는 것인데, RDBMS는 데이터 중심으로 구조화되어 있고, 집합적인 사고를 요구한다.
- 객체지향에서 이야기하는 추상화, 상속, 다형성 같은 개념이 없다.
객체와 관계형 데이터베이스는 지향하는 목적서로 다르므로 둘의 기능과 표현 방법도 다르다.
- 이것을 객체와 관계형 데이터베이스의 패러다임 불일치 문제라한다.
- 따라서 객체 구조를 테이블 구조에 저장하는 데는 한계가 있다.
1.2.1 JPA와 상속
- JPA는 상속과 관련된 패러다임의 불일치 문제를 개발자 대신 해결해준다.
- 개발자는 마치 자바 컬렉션에 객체를 저장하듯이 JPA에게 객체를 저장하면 된다.
1.2.2 연관관계
- 객체는 참조를 사용해서 다른 객체와 연관관계를 가지고 참조에 접근해서 연관된 객체를 조회한다.
- 객체는 참조가 있는 방향으로만 조회 가능
- 반면에 테이블은 외래 키를 사용해서 다른 테이블과 연관관계를가지고 조인을 사용해서 연관된 테이블을 조회한다.
- 테이블은 외래 키 하나로 모든 테이블 조회 가능
1.2.3 객체 그래프 탐색
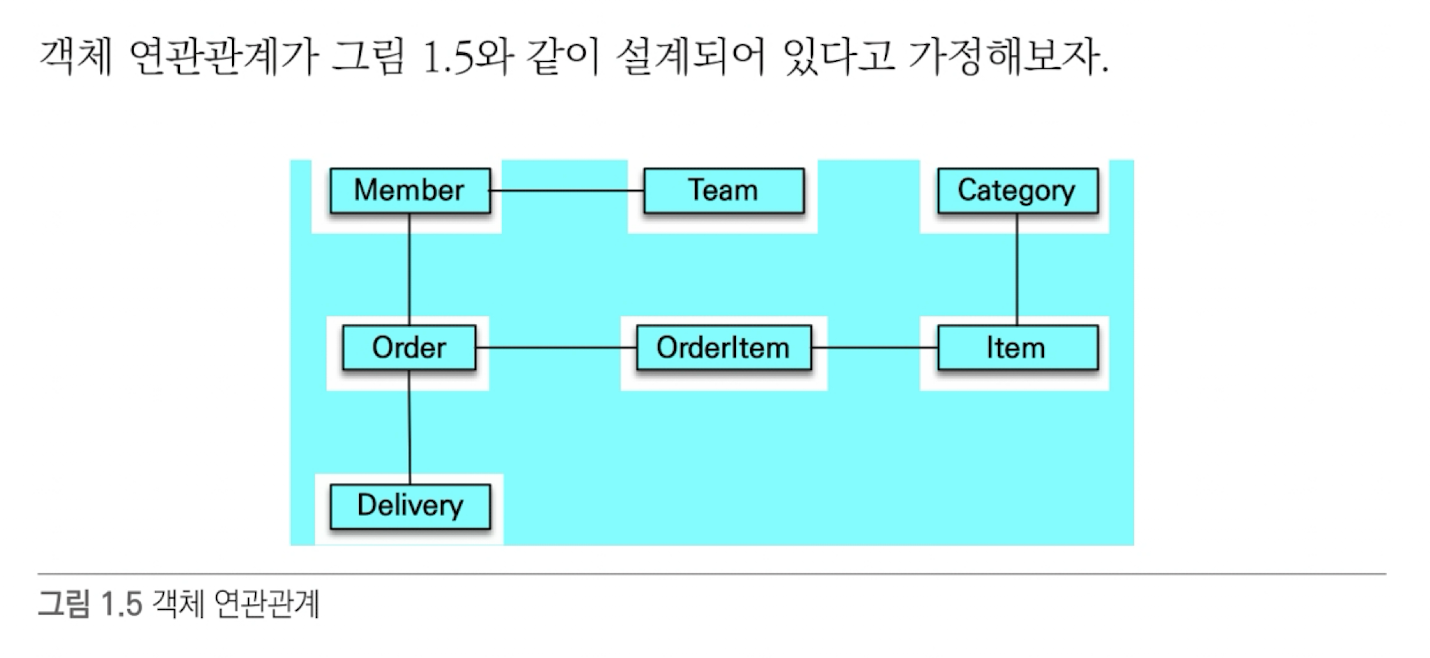
객체에서 회원이 소속된 팀을 조회할 때는 다음처럼 참조를 사용해서 연관된 팀을 찾으면 되는데, 이것을 객체 그래프 탐색이라 한다.
val team = member.team//kotlin 코드- 객체는 마음껏 객체 그래프를 탐색할 수 있어야 한다.

SQL을 직접 다루면 처음 실행하는 SQL에 따라 객체 그래프를 어디까지 탐색할 수 있는지 정해진다.
이것은 객체지향 개발자에겐 너무 큰 제약이다.
왜냐하면 비즈니스 로직에 따라 사용하는 객체 그래프가 다른데, 언제 끊어질지 모를 객체 그래프를 함부로 탐색할 수는 없기 때문이다.
DAO(데이터 접근 계층) 을 열어서 SQL을 직접 확인해야 한다.
엔티티가 SQL에 논리적으로 종속되어서 발생하는 문제
JPA와 객체 그래프 탐색
- JPA는 연관된 객체를 사용하는 시점에 적절한 SELECT SQL 을 실행한다.
- 따라서 JPA를 사용하 면 연관된 객체를 신뢰하고 마음껏 조회할 수 있다.
- 이 기능은 실제 객체를 사용하는 시점까지 데이터베이스 조회를 미룬다고 해서 지연 로딩이라 한다.
- JPA는 지연 로딩을 투명(transparent) 하게 처리
- JPA와 관련된 또 다른 코드를 심을 필요가 없다.
1.2.4 비교

데이터베이스는 기본 키의 값으로 각 row를 구분한다.
반면에 객체는 동일성(identity) 비교와 동등성(equality) 비교라는 두 가지 비교 방법이 있다.
따라서 테이블의 로우를 구분하는 방법과 객체를 구분하는 방법에는 차이가 있다.
- 이런 패러다임의 불일치 문제를 해결하기 위해 데이터베이스의 같은 로우를 조회할 때마다 같은 인스턴스를 반환하도록 구현하는 것은 쉽지 않다.
- 여기에 여러트랜잭션이 동시에 실행되는 상황까지 고려하면 문제는 더 어려워진다.
JPA와 비교

- JPA는 같은 트랜잭션일 때 같은 객체가 조회되는 것을 보장한다.
1.3 JPA란 무엇인가?
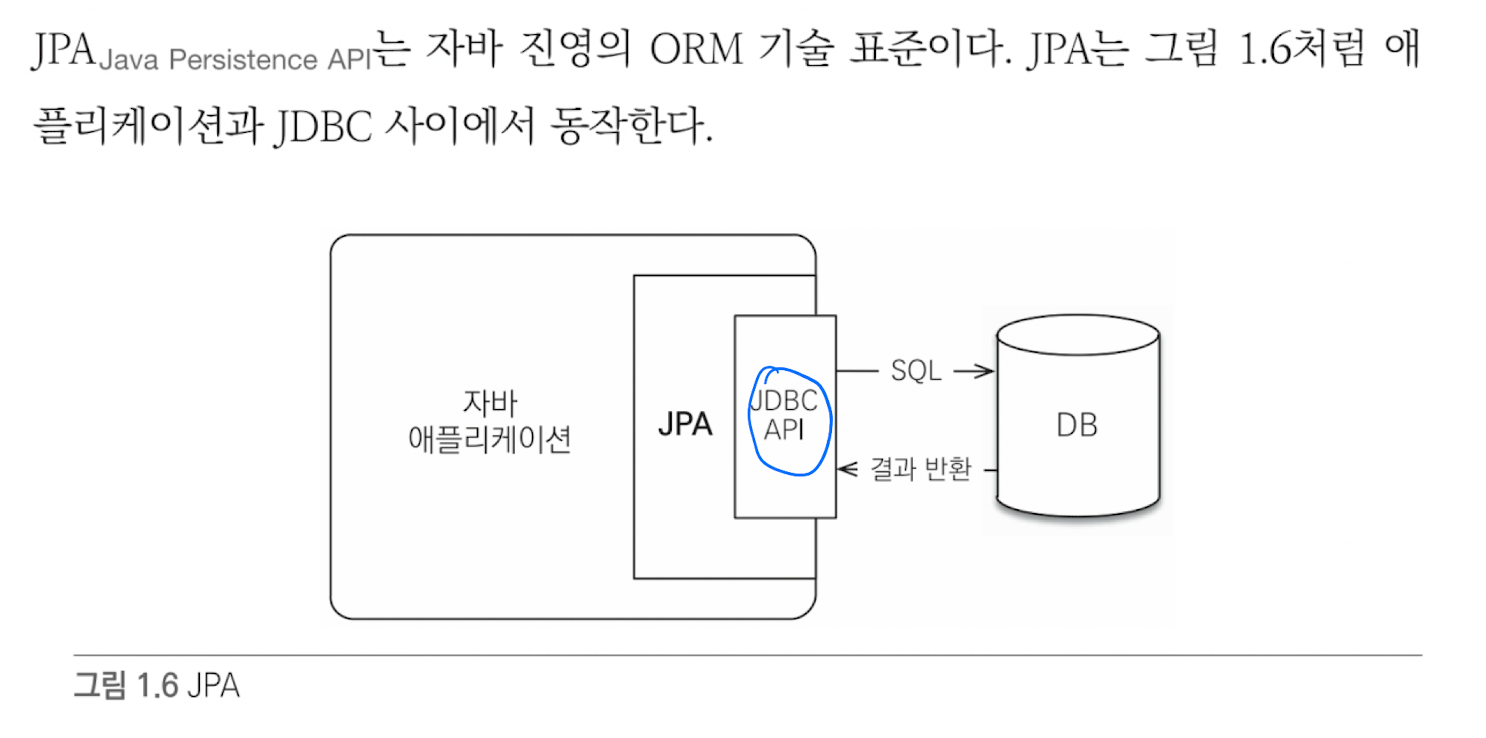
ORM(Object-Relational Mapping) 이란 이름 그대로 객체와 관계형 데이터베이스를 매핑한다는 뜻
ORM 프레임워크는 패러다임의 불일치 문제를 개발자 대신 해결해준다.
- 예를 들어 ORM을 사용하면 객체를 데이터베이스에 저장할 때 INSERT SQL을 직접 작성하는 것이 아니라
- 객체를 마치 자바 컬렉션에 저장하듯이 ORM 프레임워크에 저장하면 된다.
- 그러면 ORM 프레임워크가 적절한 INSERT SQL을 생성해서 데이터베이스에 객체를 저장해준다.
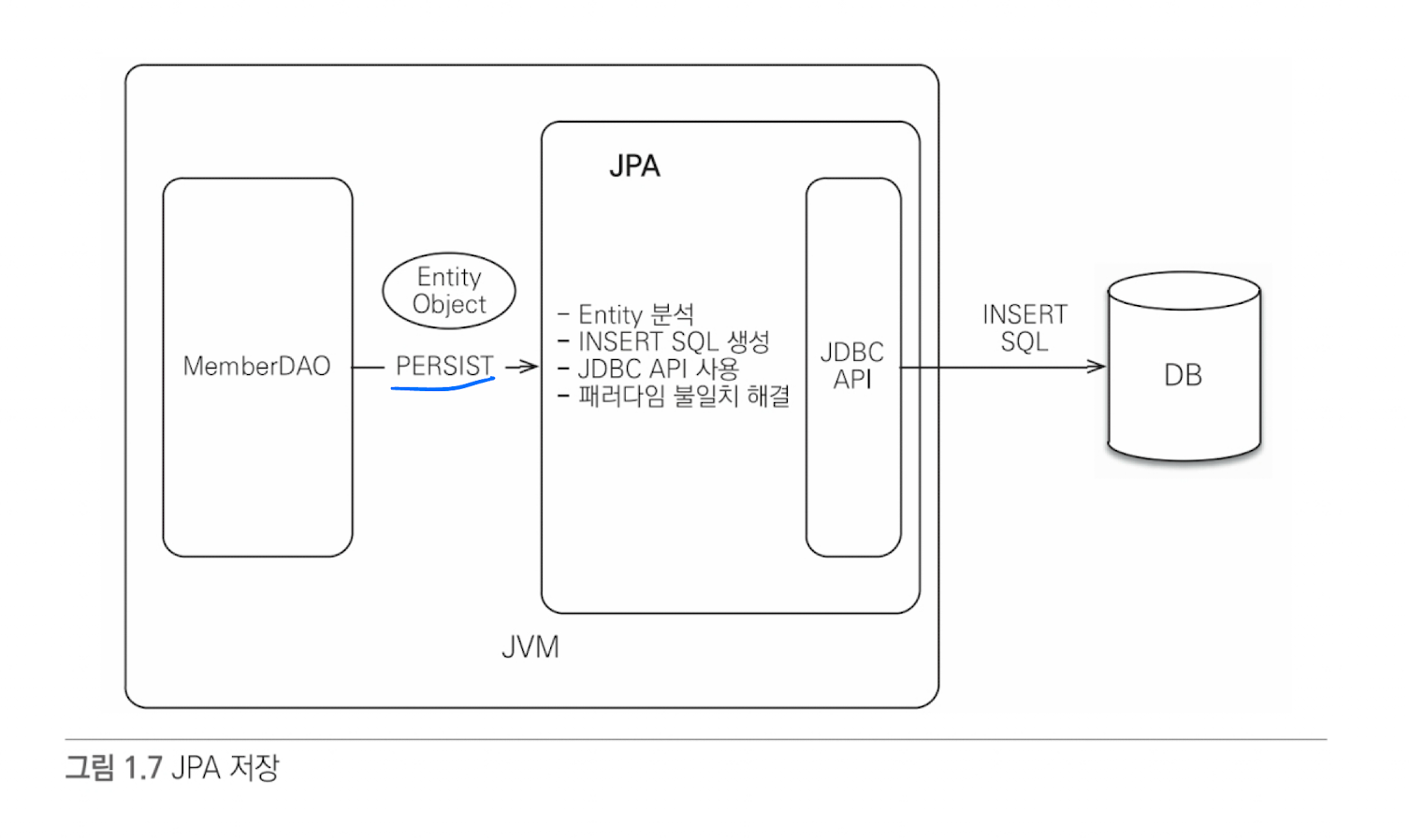
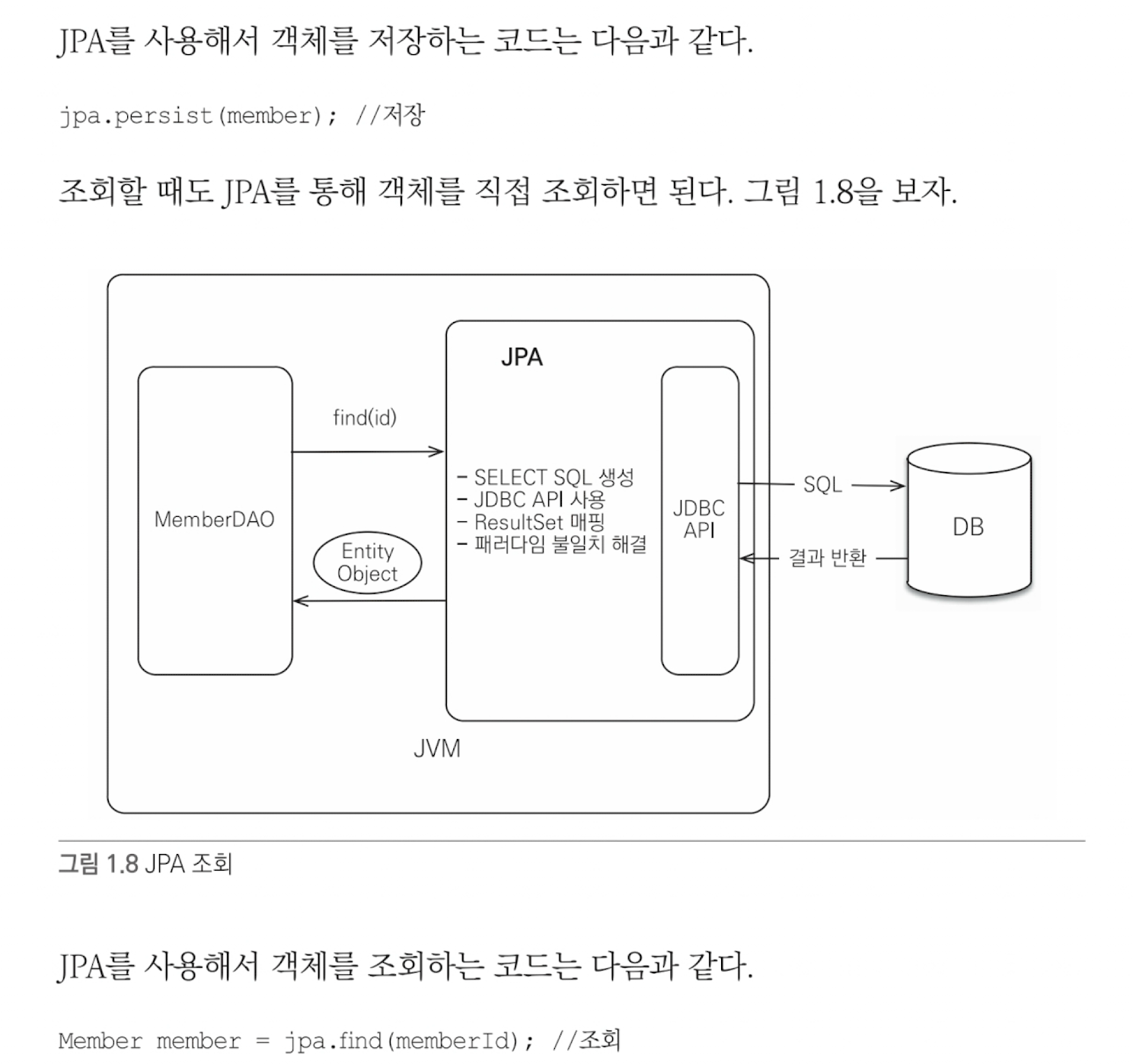
ORM 프레임워크는 단순히 SQL을 개발자 대신 생성해서 RDBMS에 전달 해주는 것뿐만 아니라, 다양한 패러다임의 불일치 문제들도 해결해준다.
따라서 객체 측면에서는 정교한 객체 모델링을 할 수 있고 관계형 데이터베 이스는 데이터베이스에 맞도록 모델링하면 된다.
- 둘을 어떻게 매핑해야 하는지 매핑 방법만 ORM 프레임워크에게 알려주면 된다.
- 덕분에 개발자는 데이터중심인 관계형 데이터베이스를 사용해도 객체지향 애플리케이션 개발에 집중할수 있다.
자바 진영에도 다양한 ORM 프레임워크들이 있는데 그중에 하이버네이트 프레임워크가 가장 많이 사용된다.
- 하이버네이트는 거의 대부분의 패러다임 불일치문제를 해결해주는 성숙한 ORM 프레임워크다.
1.3.1 JPA 소개
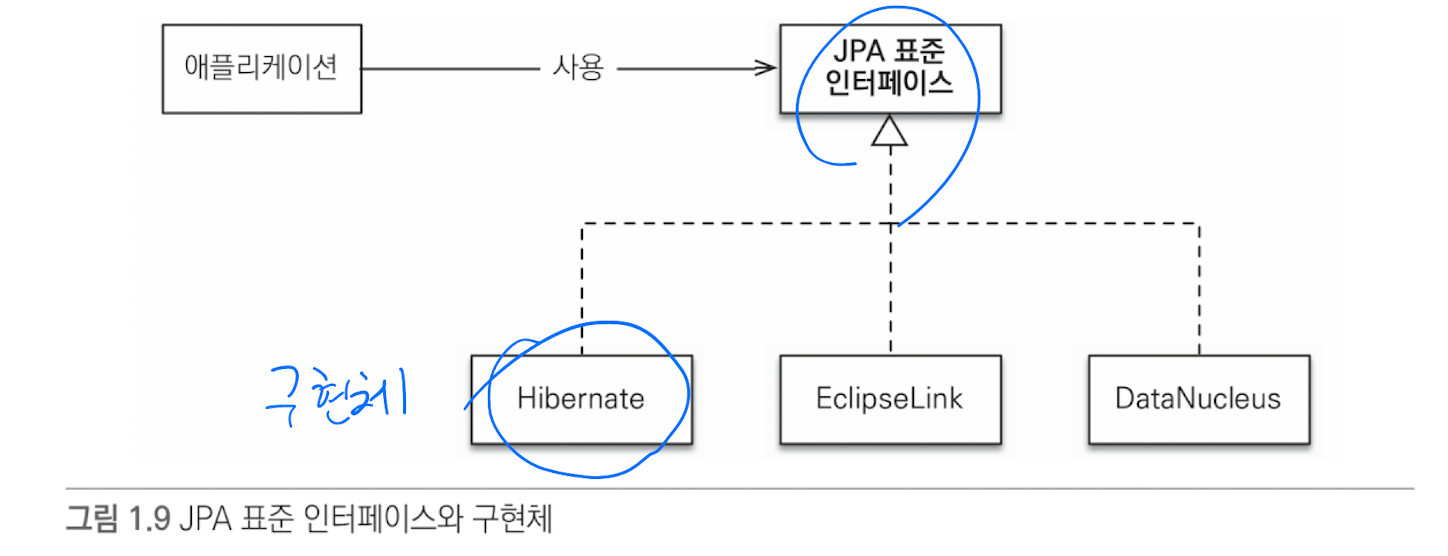
- JPA는 자바 ORM 기술에 대한 API 표준 명세, 인터페이스를 모아 둔 것
- JPA 표준은 일반적이고 공통적인 기능의 모음
- 표준 덕분에 특정 구현 기술에 대한 의존도를 줄일 수 있음, 다른 구현으로 쉽게 이동 가능
- JPA를 사용하려면, JPA를 구현한 ORM 프레임워크를 선택해야 한다
- 하이버네이트가 가장 대중적
1.3.2 왜 JPA를 사용해야 하는가?
생산성
복잡한 SQL와 JDBC API를 다루는 일을 대신 해줌
데이터 중심 -> 객체 중심으로 역전 가능
유지보수
JDBC API 코드를 대신 처리
유연한 도메인 모델을 편리하게 설계가능
패러다임의 불일치 해결
성능
- 트랜잭션 안에서 두 번 조회할 때, 조회한 객체 재사용 가능하기에 SELECT SQL 를 한 번만 데이터베이스에 전달
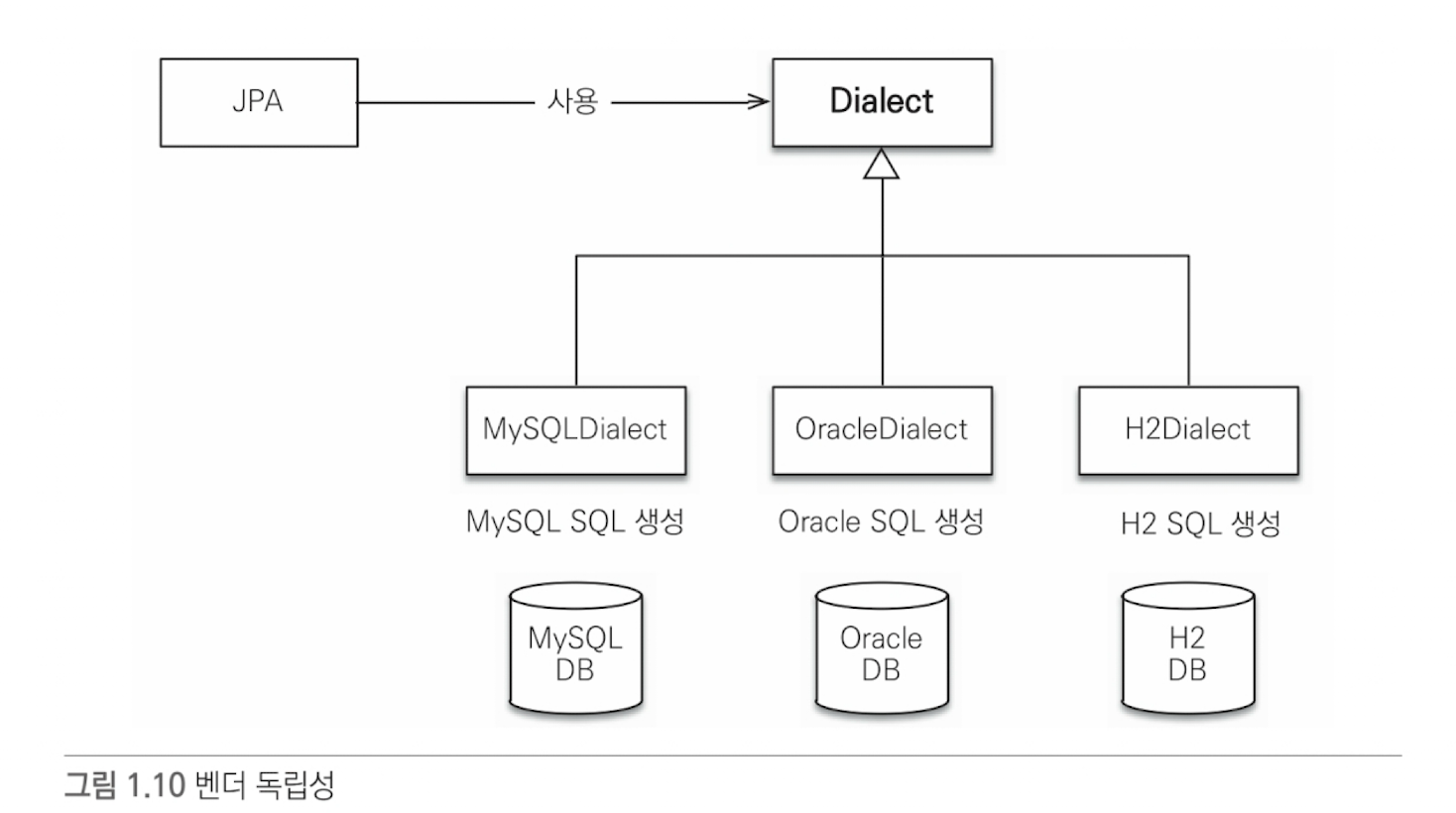
데이터 접근 추상화와 벤더 독립성
App과 DB 사이에 추상화된 데이터 접근 계층을 제공
데이터베이스 특정 기술에 종속되지 않게 됨
표준
- JPA는 자바 진영 ORM의 기술 표준이다.
- 표준 덕분에 특정 구현 기술에 대한 의존도를 줄일 수 있음, 다른 구현으로 쉽게 이동 가능
Reference
- 자바 ORM 표준 JPA 프로그래밍 (김영한) https://product.kyobobook.co.kr/detail/S000001766367